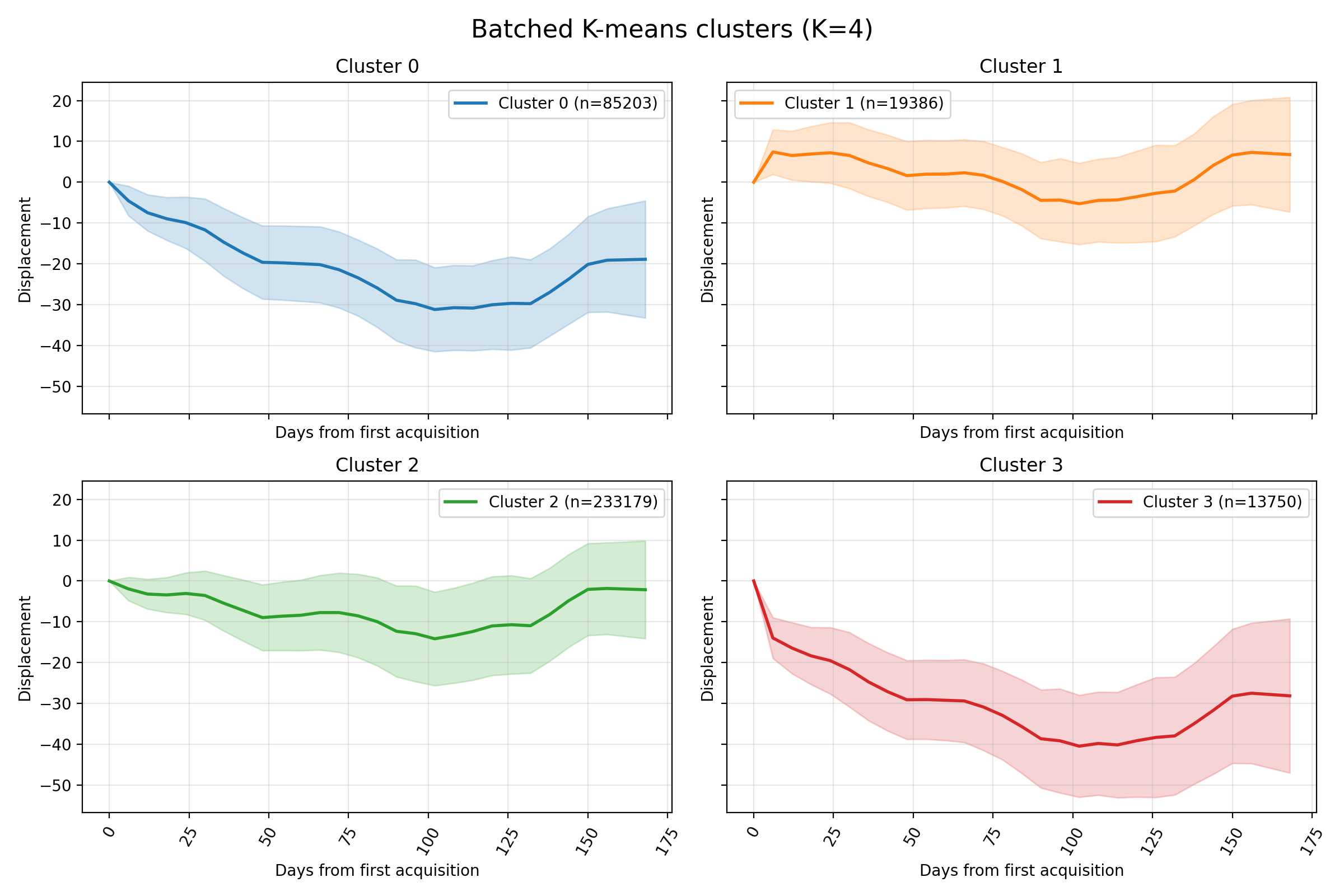
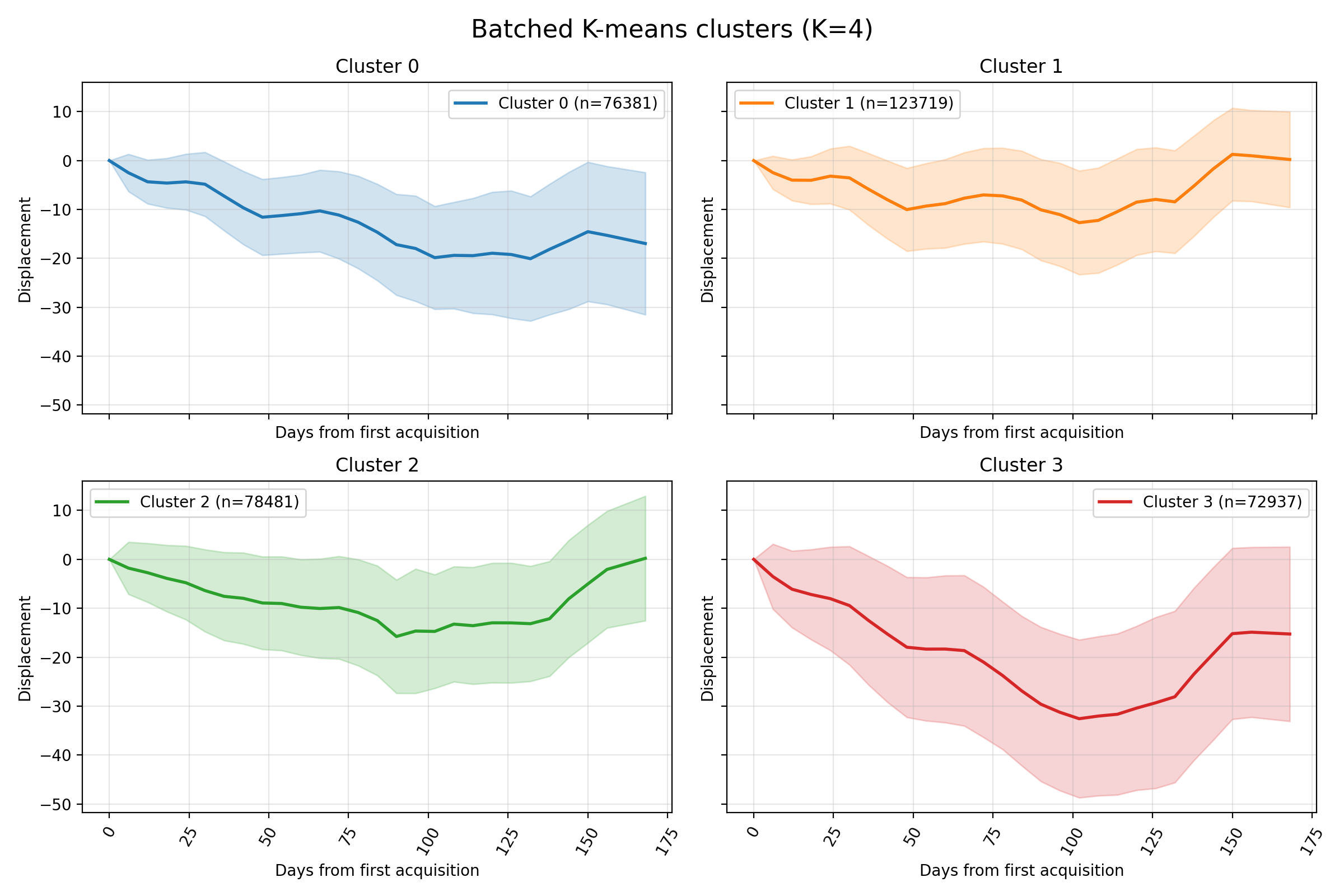
Mini-batch $k$-means provides a scalable baseline to partition the InSAR catalogue into coherent deformation regimes. By processing small batches, it keeps memory usage manageable while approximating the centroid updates of classic $k$-means.
Why naive $k$-Means fails here
- Due to the size of the dataset, the full feature matrix cannot fit into memory at once.
- Standard $k$-means processes the entire dataset at once and recomputes distances to every centroid on each iteration, which would exceed both RAM and compute budgets.
- Loading the whole dataset would also break the data pipeline built around on-disk graph shards, making the workflow brittle and slow.
Batched $k$-Means overview
- Consumes only one batch of points at a time (for example 256 samples), consisting of either dynamic features only or dynamic and static features together.
- Split the data into a train and test set.
- Warm-start the centroids with a uniform sample (
S = 25,600examples) taken from the first few batches of the train loader so that the initial cluster centers already reflect the data distribution. - Continue training with
MiniBatchKMeans.partial_fit, which updates cluster centers incrementally as new batches from the train loader arrive, avoiding the need to revisit past data. - After the model is stable, sweep once more over both the train and test loaders to assign the final cluster labels
# Standard K-Means
X = load_entire_dataset() # requires all samples in memory
model = KMeans(n_clusters=k)
model.fit(X) # multiple full passes over X
labels = model.predict(X)
# Batched Mini-Batch K-Means
model = MiniBatchKMeans(n_clusters=k)
init_pool = []
for batch in stream_dataset(): # batches come from DataModule
init_pool.append(batch)
if total_samples(init_pool) >= S:
break
model.fit(concat(init_pool)) # warm-start centroids once
for batch in stream_dataset(): # second pass covers full dataset
model.partial_fit(batch) # incremental centroid updates
labels = []
for batch in stream_dataset():
labels.append(model.predict(batch))
store_results(labels)
The batched version only needs a fraction of the dataset in memory at any point, while still converging to stable clusters thanks to the incremental updates provided by MiniBatchKMeans.
Results
The dynamic features are the Reservoir embeddings.
The static features in mainland Norway (Lyngen, Nordnes) are:
- height
- mean velocity
- temporal coherence
- amplitude dispersion
On Svalbard data, the static features are:
- ELEVATION
- MAXDISP
- COHERENCE
- DEMERR
- SLOPE
- DOYMAX
Lyngen
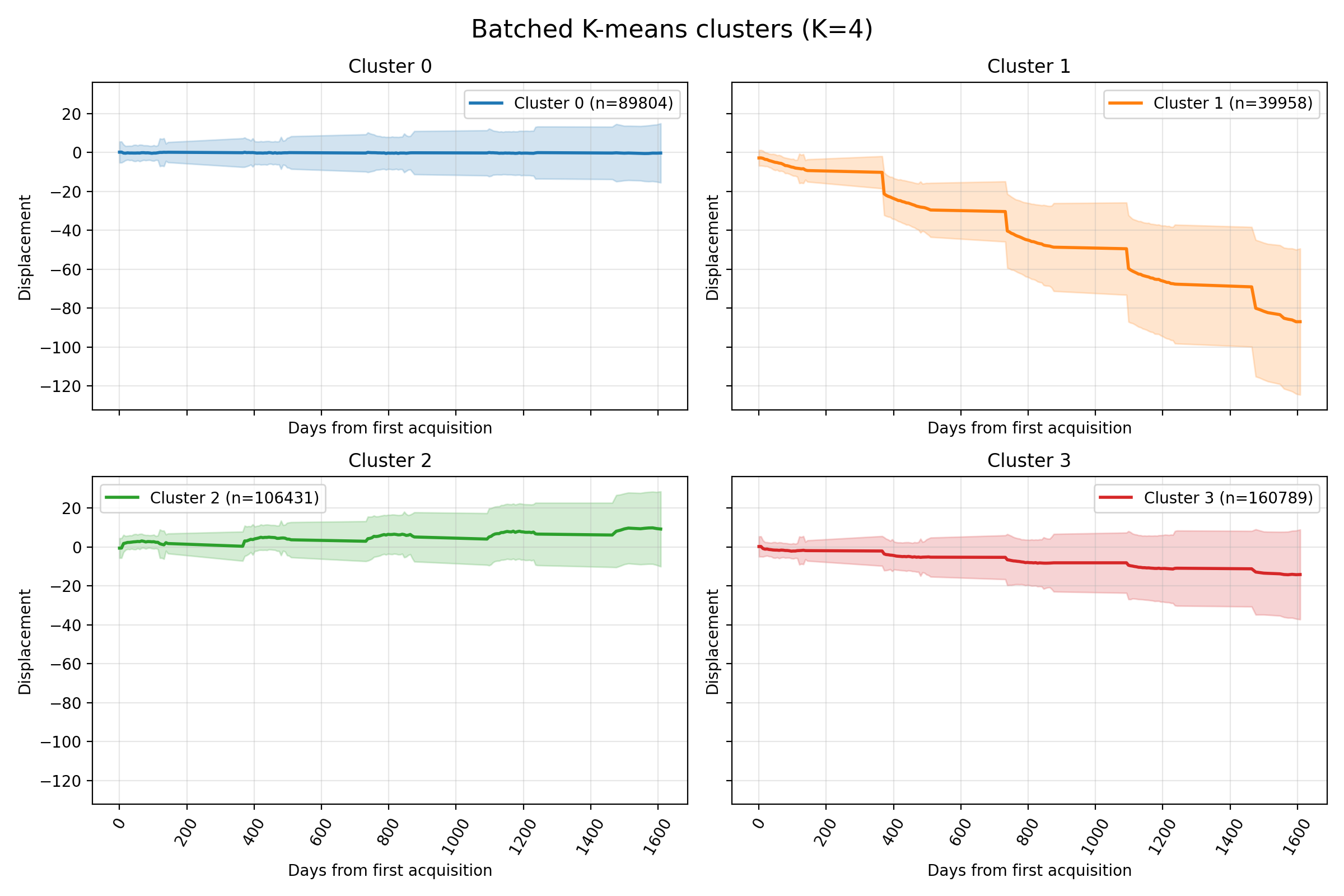
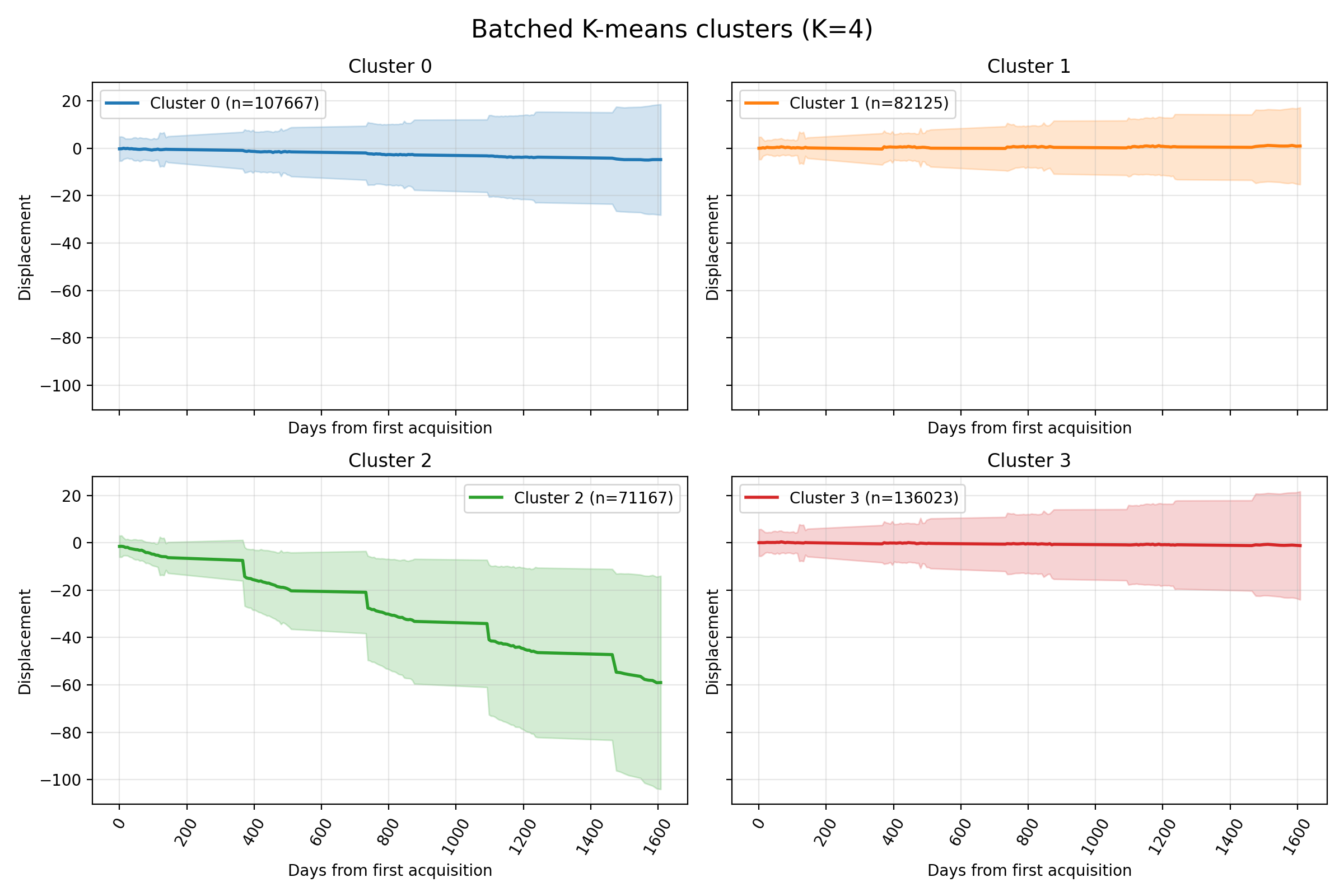
Nordnes
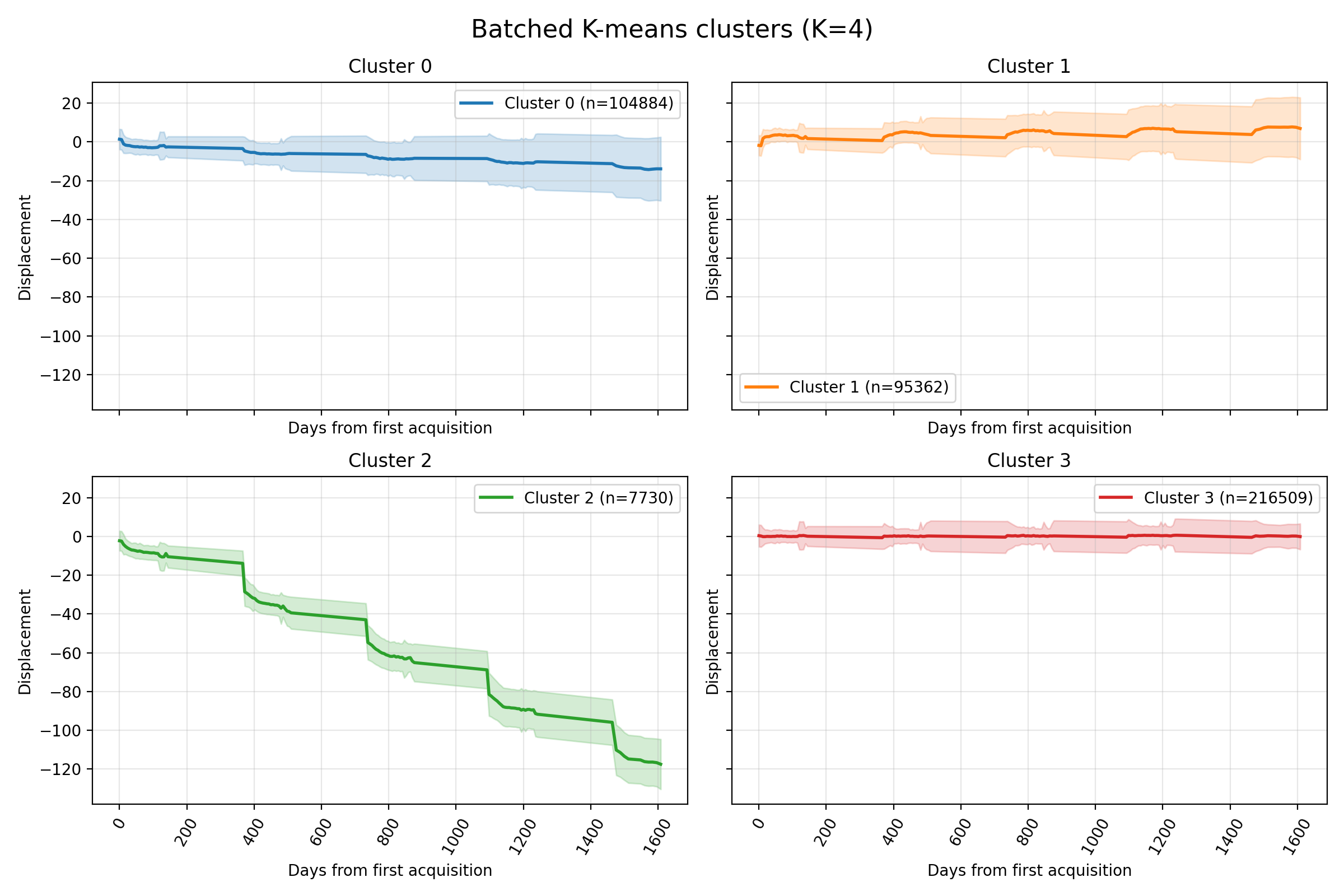
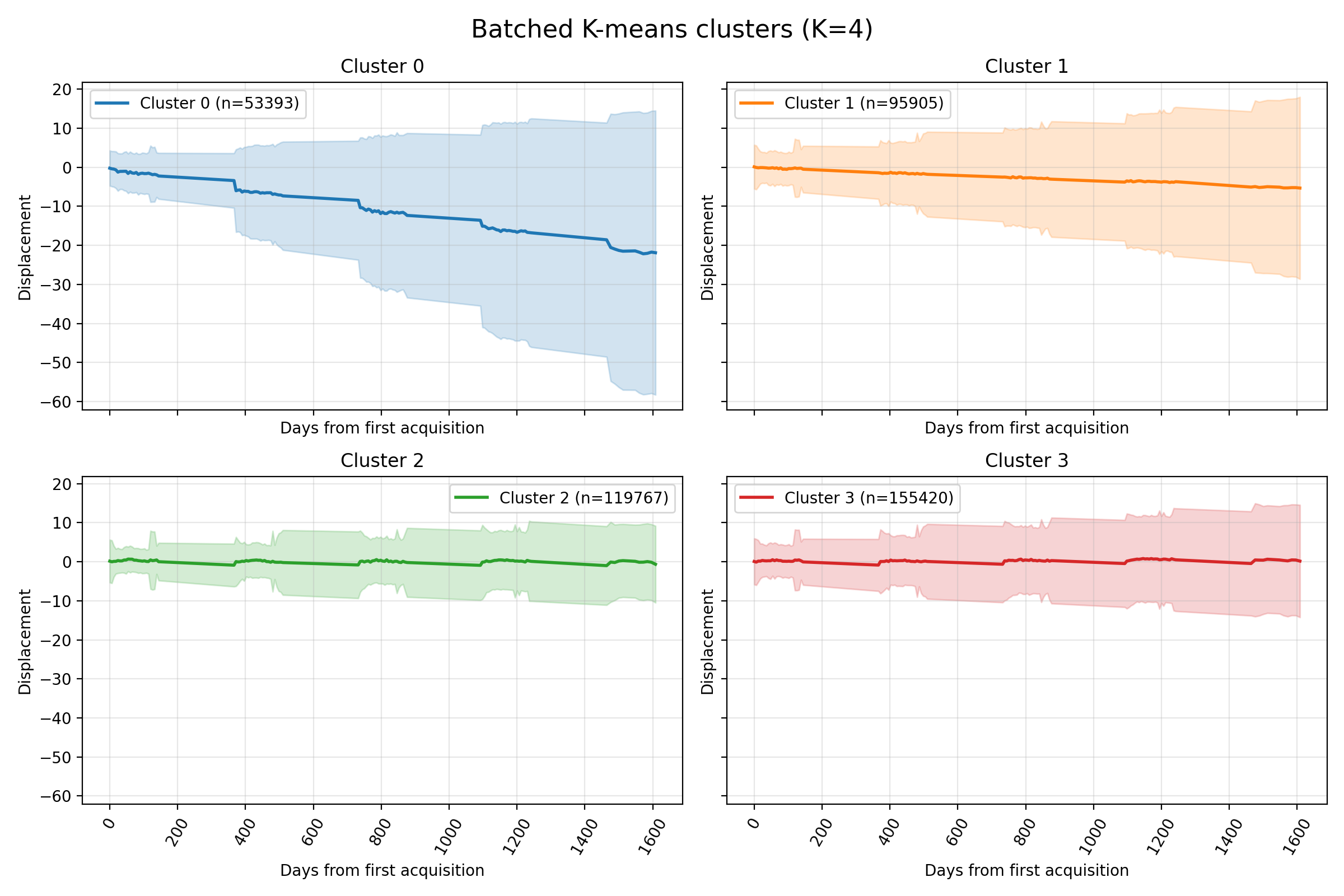
Svalbard